Bloom-Filter #
A Bloom filter can be used when you need to quickly check if a value is not present. For example, you can store different words in the Bloom filter and quickly check whether the input corresponds to a word in the filter. The advantage of the Bloom filter is the small memory space and the speed. A disadvantage is that with the help of the Bloom filter it is not possible to tell whether the value is present.
Here is a short example with single letters:
Bloomfilter von https://en.wikipedia.org/wiki/Bloom_filter#/media/File:Bloom_filter.svg lizenziert unter Public Domain
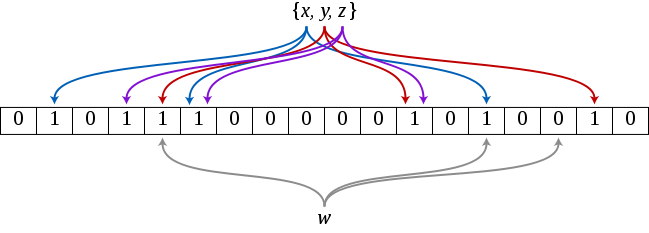
There are 3 words (general n-words) in the filter, namely “x”, “y” and “z”. The above filter consists of 18 fields (general m-fields) with one bit each. In addition, 3 hash functions are used (general k-hash functions).
If a word is to be stored in the Bloom filter, the developer must first consider how to get the word into the range [0; m). This is done with a hash function, which must also provide equally distributed results. So the result of the hash function points to the position in the array, which must be set to 1.
To make the probability of collisions smaller, multiple hash functions are used. For example, if the hash function is f(x) = x % 5 and the two words 5 and 15 are hashed, then this results in a 1 in the field 0. However, if a second hash function g(x) = x % 6 is also added, then this results in the values 5 and 3. This second hash function therefore already prevents a false positive.
In the above example, the hash values of the word “w” are {1, 5, 13}, for “y” then {4, 11, 16} and for z then {3, 5, 11}. The word “w” is definitely not in the Bloom filter because a hash value points to a location with a value of 0. The word “a” (not in the image) has the hash {1, 3, 4} and would be included according to the Bloom filter. It is a false positive because we did not include the word.
How many hash functions must be used can be calculated. This depends mainly on the size of the bit array and this in turn on the number of elements. It is relatively easy to calculate. The probability that a bit is set to 1 is \(\frac{1}{m}\) and consequently that the bit remains at 0 is then \((1 - \frac{1}{m})\) . If there are multiple hash functions or elements, the chance that the bit stays at 0 reduces to \((1 - \frac{1}{m})^{kn}\) . The probability that all bits are then at 1 is thus \((1 - (1 - \frac{1}{m})^{kn})^k\) , since k bits must be tested.
Using custom hash functions is dangerous. In the above example, the hash functions only return values from 0 to 4 and 0 to 5, respectively. The property of equal distribution is thus violated. This leads to many false positive results as well as wasting space of the other memory locations which remain 0.